7月1日,声网发布全球首个 AI 模型评测平台(对话式)。该平台针对对话式 AI 场景下,级联大模型中的ASR+LLM+TTS延迟数据提供主流供应商的横向测评,更直观的展示声网对话式 AI 引擎适配各主流模型的实时性能数据。同时,平台还提供了“竞技场”功能,开发者可自由选择 ASR、LLM、TTS 的主流供应商进行对比,根据性能延迟的数据表现,选择更适配自身业务的模型供应商。
声网对话式AI引擎在上线之初,就凭借灵活扩展的特性受到开发者的欢迎,兼容适配全球主流的大模型与 TTS 供应商,满足不同场景和业务需求。此次 AI 模型评测平台与对话式AI引擎v1.6版本联动发布,新版本对话式 AI 引擎开放了 ASR,并上线了声网自研的凤鸣-实时语音识别。同样在该评测平台,开发者也可以自主选择包括腾讯云-实时语音识别、火山引擎-实时语音识别、凤鸣-实时语音识别在内的各家供应商,进行延迟数据的对比。
ASR+LLM+TTS 延迟性能排行榜
综合最优、响应最快模型一目了然
AI模型评测平台主要分为“仪表盘”与“竞技场”两项功能,在“仪表盘“中官方推荐了对话式 AI 引擎适配后综合最优、响应最快的级联模型组合。例如,截止目前,综合最优推荐级联模型组合为腾讯云-实时语音识别+阿里云-通义千问 Turbo+火山引擎-语音合成。响应最快推荐级联模型组合为凤鸣-实时语音识别+智谱-GLM 4 AirX+百度智能云-语音合成,级联模型总延迟为1125.36 ms。
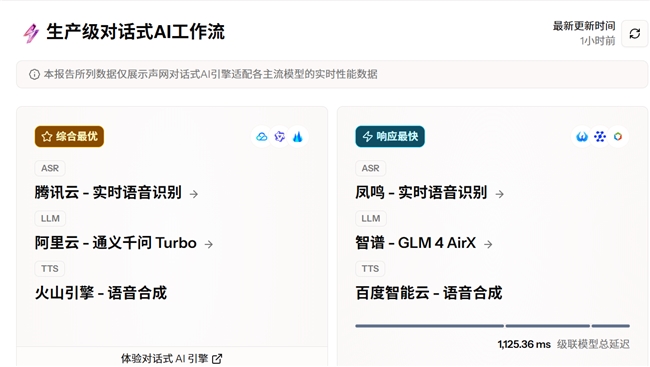
同时,“仪表盘”专为对话式AI 场景定制了多个级联模型延迟数据排行榜,且评测数据保持每小时更新:
1、Top 10 级联模型组合:以级联模型总延迟为评测指标,直观的展示不同组合级联模型的总延迟数据对比;
2、语音识别(ASR) Top 3 :以末字延迟为评测指标进行对比;
3、语言模型(LLM) Top 3 :以首字延迟的性能数据进行排序;
4、语音合成(TTS) Top 3 :对比各家TTS 供应商的首字节延迟性能。

竞技场自主选择模型性能对比
支持TTS测试语句试听
在 AI 模型评测平台“竞技场”中,开发者可自主选择不同的 ASR、LLM、TTS 模型进行延迟性能的对比。例如 LLM 可选择 DeepSeek V3、豆包大模型、智谱 GLM 系列模型、 通义千问系列模型、MiniMax Text 01、腾讯云混元系列模型等进行对比;ASR-实时语音识别和 TTS-语音合成也包含了市场各家主流模型。
针对延迟数据的评测指标,平台还提供了多个分位的延迟数据差异对比,从 P25、P50 到 P99 共六个分位,开发者可以更详细的了解每个模型的延迟数据表现。例如,凤鸣-ASR P50分位的末字延迟为572 ms,意味着测试期间50%的延迟数据低于572 ms。
此外,“竞技场”的 TTS-语音合成对比中,还提供了预设的语音合成测试语句,反映多种场景下(字母数字混合、非流畅性语句、客户服务、医疗健康、外呼销售、有声书&播客、非常见发音词汇)不同模型的语音合成质量,并且支持试听。

目前,AI模型评测平台已正式上线声网官网,未来声网也将持续更新模型成本、单词准确率等新的评测维度,助力开发者更好的选择适配自身业务的最优模型组合。
如您想进一步体验 AI模型评测平台,可进入声网官网的“对话式AI”页面进行体验。















